杨 丹
(北京东华合创科技有限公司,北京 110190)
当前,越来越多防灾防汛部门意识到现代化信息技术能够为防汛抗洪带来巨大的帮助,适当的采用信息技术有利于设计出高效、可靠的水利防灾信息检索模型,可以在发生洪水等灾难时,迅速地掌握灾情状况,并预测关于暴雨、洪水等灾难的信息,以便更加科学、有效地制定防汛抗洪方案,提前发布警报,在有限的工程条件下减少灾难带来的损失。目前已存在大量信息检索方法用于水利防灾领域[1]。文献[2]基于贝叶斯网络的信息检索方法是通过对检索关键词代表的所有主题领域进行泛化训练,将得到的训练模型与自然语言模型相结合,构建双重信息检索模型;
文献[3]基于关联规则挖掘的信息检索方法通过数据匹配,挖掘检索数据与数据库中信息的关联度,将具有相似语义的信息整合在一起,构成具有逻辑关系的内部数据库,进而实现信息检索。但上述两种方法是否适用于多尺度、大规模的信息检索中还需进一步研究。本文提出的基于属性提取的水利防灾信息检索模型,结合信息属性参数和映射连接关系,完成水利防灾信息的属性提取。以数据信息属性为基础,采用二叉树算法构建信息检索模型。基于检索模型,将用户检索行为发生的时间作为检索控制标准,输出最佳检索结果,为当今大数据时代的检索任务提供了一种可行的解决方案。
1.1 水利防灾信息属性提取
若想实现信息的快速检索,则需要对系统数据库中的信息进行属性提取,包括信息的主键、索引字段以及索引类型等,按照水利防灾属性数据库检索方式,按照信息属性对关键词、代表领域等进行划分[4]。水利防灾属性数据库及主要信息见表1。

表1 水利防灾信息属性数据库及主要信息
服务器后台数据库共由19个表组成,假设在计算机中,数据库中的信息数据均处在多维度的空间内,在此基础上,提出了一种基于二进制的方法,并对其进行了逆向表示;
在系统中,通过使用本体库来替代用户在搜索过程中所输入的关键字,用来描述系统内的大量信息[5]。在此基础上,利用服务器上的索引信息,对数据进行连接映射处理。处理过程中,可以通过在资源信息终端和接收端间建立链表以实现初始检索。资源信息与接收端口的映射连接如图1所示。

图1 资源信息与接收端口的映射连接图
水利信息与接收端通过关系组连接,由于信息来源是多渠道的,数据信息结构也不相同,因此,利用节点平滑公式对多源信息的节点进行平滑化,计算公式如下:
(1)
式中,τ—检索信息时的时延,s;
X—检索信息的字节长度;
p—在检索过程中受到节点变化的影响参数;
n—用户检索信息时提供的端口数量;
i—端口序号。
通过以上计算与处理过程,结合信息属性参数和映射连接关系,实现水利防灾信息的属性映射和信息属性数据的提取。
1.2 基于二叉树算法构建信息检索模型
本文以数据信息属性为基础,参照信息检索框架,建立信息检索模型。信息检索框架如图2所示。
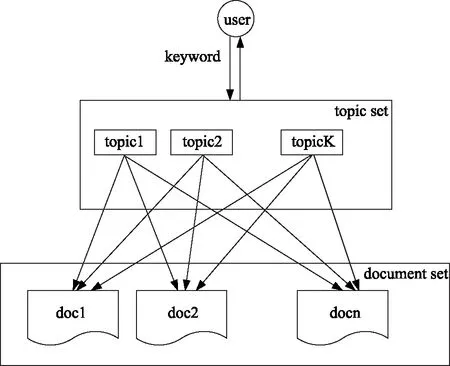
图2 信息检索框架
在信息检索系统中,话题根据不同文档的属性特征进行随机组合,组合后的话题依据文档中的先验知识生成信息源,因此,本文利用二叉树算法根据第一层的信息源建立信息检索模型。二叉树算法示意图如图3所示。

图3 二叉树算法示意图
根据图3,随着系统中信息源上的窗口随机滑动,下面的信息解析层和信息表现层也随之改变。当信息源当前窗口中有8个数据时,信息解析层就包含4个数据,信息表现层就包含2个数据[6]。而窗口的滑动会造成数据越界情况发生,因此,该模型将各层滑窗的分解结果暂存在临时数组中,当信息源窗口有新信息进入时,对应的临时数组也随之更新,由此一来,就防止了数据越界对模型的干扰。
根据二叉树在临时数组中对数据的存储结构,可以得知,当二叉树分解出j个分支时,在下一层上就包含2j个分支,同时也表示该层的信息数据共有2j组合方式。
水利信息的对象层包括道路层、居民地及地名注记层、行政区划层、等高线层、风险地带层、水工程层、水库层、河流层和水情测报站层。以上9层的位置始终保持不变,当用户进行信息检索时,可以自行决定是否对单一图层进行装载与是否标注关键信息。当用户选择需要检索的图层时,当前选中记录集会产生相应的变化,此时,信息解析层根据时间顺序依次读取检索记录,生成检索字段的值,并将更新的值插入到原队列中,取代原有字段,以保证用户在下次检索时,查询到的信息是代表当前检索环境的信息[7]。另外,用户在查找信息记录时,当找到表现层中对应的信息记录时,可以根据该记录信息的位置与范围将图层定位到包含该信息的位置。
在对信息检索的过程中,检索到的主题和文件所表达的信息也是不确定的。对于其中的每一个词项,信息检索模型所产生的词项都是一种随机的事件,其产生的几率可以表示该种可能的大小。同时,在信息检索模式中,查询主题中的词项是互相独立的[8]。因此,利用二叉树算法对信息数据进行解析后构建的信息检索模型可表示为:
P(w|D)=(1-λ)τPLM(w|D)+
λPLM(w|coll)τ+PLightLDA(w|D)
(2)
式中,PLM(w|D)—检索关键词w在文档D中出现的频率;
PLM(w|coll)—检索关键词w在整个信息数据集中出现的频率;
λ—加权系数;
τ—信息接收的延迟时长(s);PLightLDA(w|D)—在主题信息下的文档表示。
PLightLDA(w|D)的计算同样是利用二叉树算法,同时结合数据并行化和模型并行化技术,对于某篇文档PLightLDA(w|D)的生成过程如下:
在系统中的数据库中从超参数为α的信息数据分布中随机抽取部分数据,构成名为di的文档,该文档服从多项式分布θi;
在话题组合中再次随机抽取部分数据生成词项文档,文档中的第k个词对应的话题zik;
在从超参数为β的信息数据分布中抽取数据构建话题zik对应的索引词分布φzik;
在φzik中采样最终得到词项wik。重复以上步骤,将上述分布主体与分布词项进行整合,即可生成所需文档PLightLDA(w|D)。生成PLightLDA(w|D)的图模型结构如图4所示。

图4 生成PLightLDA(w|D)的图模型结构
图4中,α表示整个信息数据集的线性组合系数,通常通过人工选择确定;
β表示信息在窗口内滑过的点数;
Z表示文档中检索的主题;
φ表示词项的多项式分布;
K表示文档中包含的主题数量;
θ表示主题的多项式分布;
w表示某一个词项;
N表示信息数据集中包含的文档数量;
Nd表示该文档中包含的词项数量。
对信息检索进行建模,PLightLDA(w|D)的生成是信息检索的关键部分,在信息主题容量较大的情况下,通过调节文档相关参数,既可以使模型精确地表示出不同话题组合,也可以提高检索性能。
1.3 信息检索输出
基于构建的信息检索模型,本文根据用户进行检索时利用的信息检索关键词出现的频数,将其看作用户检索的感兴趣方向,并根据频率高低赋予其相应的权重。故为实现信息检索输出结果的准确性和具有代表性,需要对系统中信息数据进行归类,明确其中的分布规律[9]。在归类过程中,信息应当遵循这样的规律,即假设Q表示系统中的全部信息内容,T代表用户在检索时输入的关键词,因此,在出现的第一个信息数据Q1,T在里面属于第一价值信息;
在Q2与Q3信息中,T属于中间价值信息;
而在Qn信息中,T属于不重要信息。所以,参照上述规律,可将系统中信息数据按照价值重要性进行归类描述,具体计算公式如下:
(3)
式中,M—按照重要性排序的信息构成的数据集;
S—用户输入的关键词中索引类型的排列;
t—满足条件可执行快速检索行为发生的时间,s;
i—用户检索次数;
P(w|D)—信息检索模型。
则水利防灾信息数据检索输出结果可表示为:
Tcg=M×(ko)+Z(zf,zt)bf
(4)
式中,M—信息综合特征参数,ko={0,1,…,x};
Z—文档中检索的主题;
(zf,zt)—信息数据适应度参量;
bf—最小化增量拉格朗日函数。
根据以上分析与计算过程,将用户检索行为发生的时间t作为快速检索控制标准,对检索关键词进行优先级排序,当排序完成后,执行信息检索操作[10]。利用信息检索模型在系统中检索所需主题下的所有相关文档,将系统中检索出的多种资源信息进行叠加,并以此作为依据,将重叠数据置乱重构,作为寻找到的信息集合的参考项,输出信息检索结果[11- 12],进而完成对水利防灾信息的快速检索。信息检索流程如图5所示。
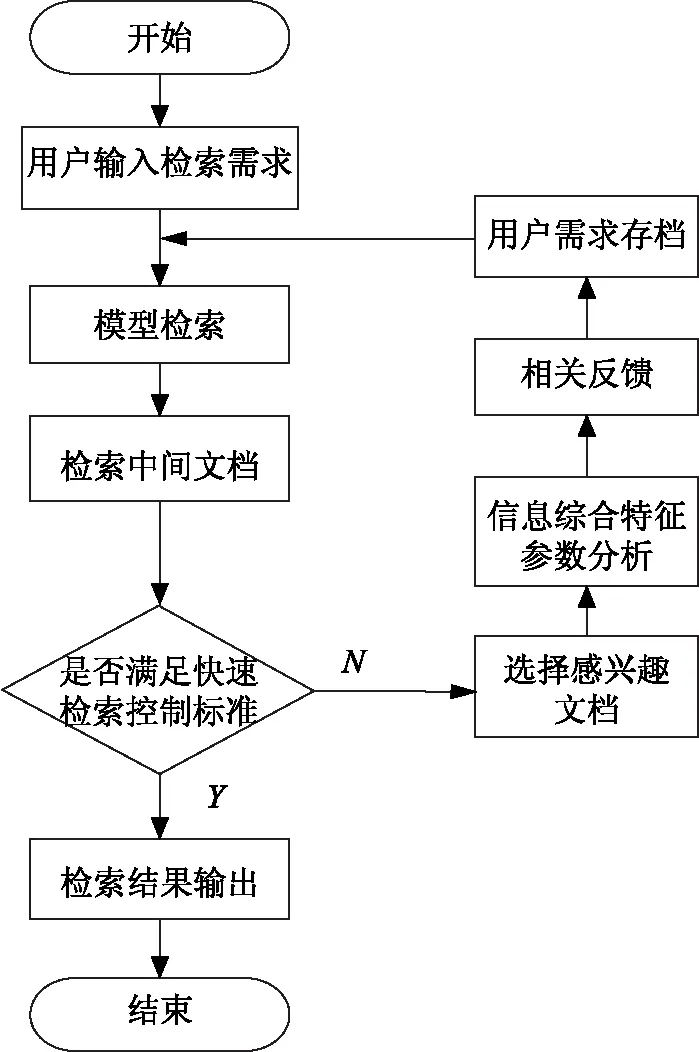
图5 信息快速检索流程图
在检索的整体过程中,若检索结果没有满足用户的需求,用户可以在上述的结果中选择感兴趣的文档,然后系统通过对该文档进行分析,获得用户的偏好,并对此进行存档,以丰富系统信息主题内容,对用户的需求进行进一步的优化,然后再次利用优化后的需求进行检索,直到检索结果满足用户的需求,将结果输出。
为证明本文设计的水利防灾信息快速检索方法能够满足实际应用需求,分别采用文献[2]基于贝叶斯网络的信息检索方法(方法1)、文献[3]基于关联规则挖掘的信息检索方法(方法2)与所提方法进行实验对比分析。
2.1 实验准备
本实验选择了某水利部门的防旱防涝单位作为实验对象,其工作原理是利用江河流域的自动监测站收集水位数据,再发送给数据通信卫星,由卫星将数据传输给防汛抗旱指挥部,在通过卫星数据接收设备转换后传送到计算机数据库服务器,并保证系统每隔10s对数据库进行一次访问,以获取最新的数据并对数据进行分析和处理,最后使用GIS技术将结果以多种形式表示出来。以上各项功能均可在内网企业网内进行,并可利用Internet网远程或实地利用无线网络进行实时查询水灾或灾难情况。选用服务器数据库中的5个数据集,在这些数据集中,查找数据库中水利防灾话题的标题,借助TREC检索会议系统搜索出相关文档集合,并进行相关性判断。若在一个数据集中,某个检索项在相关文档集合中没有所属文档,则在该数据集中剔除该检索项。数据集的统计信息见表2。

表2 数据集统计信息
在实验中,采用Windows Server 2008 R2 Enterprise服务器2台。1台主要用于训练主题信息;
另1台主要用于做检索模型实验。采用Java语言的软件环境,Lucene开源项目与微软开源的LightLDA。在此平台上进行信息检索模型测试,可以有效验证本文方法的实用性。
2.2 实验说明
由于实际检索时,用户往往只输入少量的关键字进行检索,对此,在上述实验平台的基础上,本实验只采用查询信息中的标题作为查询关键词来检索文档。在预处理过程中,我们采用了通用的停用词集合,词干则采用Porter Stemmer算法。
实验前经过数据训练以及计算,确定本文设计的检索模型中的加权系数λ取为50,数据集线性组合系数α取为0.01,主题数目K取400,训练主题信息时的迭代次数为500。因为很多关键词具有不同的特征,所以实验中的信息检索主要为多尺度查询,查询示例如图6所示。

图6 多尺度查询主题汇总信息文件中的内容
如图6所示,文档开头的“0”没有任何实际的含义,之后按照文档,主题,词项信息等从0开始依次递增。在此实验中指定了400个主题,因此在结束后的最后一个编号是399,这个文档记录的是从0,1,2,…到399是对应的被标记词项的总数。
2.3 信息检索查准率实验分析
在信息检索、分类、识别等领域中,查准率是评价检索方法性能优劣的最基本的指标,即输出的检索结果中与检索相关文档的信息数量与检索到的所有信息数量的比值(%),查准率越高,表明该方法信息检索准确率越高。为了直观地比较出3种检索方法在不同数据集上的查准率,分别将3种方法应用于上述5种数据集,得到的统计结果及对比如图7所示。
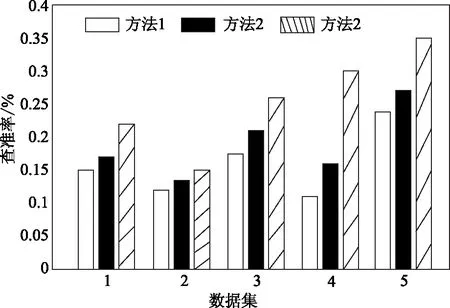
图7 实验对比结果
由图7可以看出,在不同类型的数据集上,方法1的检索准确率均相对较低,主要成因是该方法建立的检索模型对参数的敏感性较高,初始参数的设置对模型的稳定性会产生一定影响,该方法在实验前需要进行多次主题信息训练,以获取Markov链的最佳值,从而确定模型相关参数,计算量较大,不利于检索容量较大的信息数据集;
方法2的检索准确率较于方法1有明显提高,虽然整体呈上升趋势,但是在数据集4上准确率较低,主要是因为该数据集是网页性质的水利防灾信息数据集,存在一定噪音,且数据稀疏,话题分散,因此说明方法2不适用于质量较低的数据集检索中;
而本文方法在5种实验数据集上的检索准确率均高于其他2种方法,检索性能优势比较明显,验证了所提方法在信息检索中的可行性。
在上述数据信息属性的基础上,进行节点平滑处理,并采用二叉树算法根据第一层的信息源建立信息检索模型。基于构建的信息检索模型,根据用户进行检索时利用的信息检索关键词出现的频数,根据频率高低赋予其相应的权重。最后输出最佳检索结果,实现信息快速检索。利用对比实验对所提方法进行了性能验证,结果表明,本文设计的信息检索方法的检索准确率更高,在信息检索应用中是可行有效的,能够满足实际需求。但在许多方面还不够完善,例如如何提高用户的检索效率,和提高用户对检索结果的可读性,是本文需要结合相关技术进一步研究的方向。
猜你喜欢信息检索防灾文档家庭防灾应该囤点啥?奥秘(创新大赛)(2022年6期)2022-07-29地质灾害防灾避险小常识江苏安全生产(2022年5期)2022-06-16浅谈Matlab与Word文档的应用接口客联(2022年3期)2022-05-31防灾减灾 共迎丰收之季今日农业(2021年15期)2021-11-26故宫防灾的“超强铠甲”军事文摘(2021年16期)2021-11-05有人一声不吭向你扔了个文档中国新闻周刊(2021年26期)2021-07-27基于RI码计算的Word复制文档鉴别信息安全研究(2016年4期)2016-12-01医学期刊编辑中文献信息检索的应用新闻传播(2016年18期)2016-07-19在网络环境下高职院校开设信息检索课的必要性研究新闻传播(2016年11期)2016-07-10基于神经网络的个性化信息检索模型研究现代计算机(2016年11期)2016-02-28本文来源:http://www.triumph-cn.com/fanwendaquan/gongwenfanwen/2023/0728/92591.html