杨一, 卢佩, 刘效勇*, 谢峰
(1.桂林理工大学信息科学与工程学院, 桂林 541004; 2.广西嵌入式技术与智能系统重点实验室, 桂林 541004)
生成对抗网络[1](generative adversari-al networks, GANs)的基本思想是同时训练生成式和判别式两种不同的网络,前者试图产生更接近真实的数据,而后者试图分辨真实数据与生成数据,两个网络在多次迭代对抗训练中共同学习和进步,以达到生成高质量图像的目的。
近年来,包括PGGAN[2]、StyleGAN[3]和Styl-eGAN2[4]等先进 GAN技术的不断发展,提高了生成人脸图像的质量。这些GAN生成的人脸与相机自然采集人脸相比,很难用人眼进行区分。而合成的人脸可以直接用于制造虚假信息,容易被恶意滥用,例如把名人或政客的脸换成色情图片,对个人的声誉权严重损害;也被用来制作各国领导人演讲的虚假新闻,对世界安全构成了威胁,造成国家之间的政治宗教紧张局势,也对社会的稳定安全带来严重威胁和一定的伦理道德问题。因此为了减少虚假内容带来的负面影响,利用技术检测所生成的人脸图像是十分重要的[5]。
到目前为止,人们提出专注于检测GAN生成人脸图像的算法可以大致分为两类[6]:基于手工特征和基于深度学习的方法。①基于手工特征的方法。该方法取决于图像的统计性质或固有性质,如颜色、纹理和边缘信息等,但此类方法在检测结构复杂的图像时性能较差。②基于深度学习的方法。该方法从训练数据中自动学习到给定任务的多级表示,更适合于复杂的图像。因此越来越多的研究人员选择采用卷积神经网络[7](convolution neural networks, CNN)作为获取鉴别性特征的手段。
随着基于深度学习检测方法的发展,涌现出一些基于CNN设计的模型,如Hsu等[8]将简化的 DenseNet发展成双流网络结构并使用对比损失检测生成图像,其检测性能优于其他最先进的图像检测器。Chang等[9]提出改进的VGG网络——NA-VGG来检测伪造的人脸图像,其性能与之前的网络相比提高了29.3%。Bca 等[10]使用基于Xception的改进网络得到了生成人脸区域的多尺度、多层次特征,在FFHQ数据集上进行实验并在各方面表现优秀。Fu等[11]使用高斯低通滤波器对图像预处理,采用双通道CNN网络对人脸检测,具有较好的性能。Chai等[12]使用基于补丁的分类器和有限的接收字段,使得图像被篡改的区域能够更容易被检测到。而Hasin等[13]则在Denset、VGGNet等八种不同的神经网络架构之间进行了对比,结果表明VGFacebook架构表现最好。上述文献研究表明CNN在伪脸图像检测上具有优越性。
尽管CNN在局部特征提取方面具有优势,但这些检测方法却受限于CNN接受域的性质,在对图像全局表示上遇到了困难。因此为了弥补CNN在这方面中所面临的问题,Vaswani等[14]首次提出了Transformer架构。Transformer是一种依赖于自注意力机制来构造输入和输出之间全局依赖关系的模型,没有采用原始的循环和卷积神经网络,研究表明 Transformer在图像分类、翻译等任务中能够取得满意的结果。基于此,Maaz等[15]有效结合CNN和Tansformer的优点,使用一种高效混合体系结构EdgeNeXt,利用自注意力增加感受野并编码多尺度特征,在ImageNet-1K上达到了79.4%的TOP-1精度。而Khan等[16]使用基于早期特征融合策略,采用两种不同的网络作为特征提取器,再将其输入到Transformer中进行训练。上述研究表明CNN与Transformer的结合可以取得更好的检测效果。然而,CNN与Transformer串联式网络架构并不能很好地发挥Transformer提取全局特征的特性,部分输入图像在CNN训练中存在着特征丢失的现象。随之Peng等[17]提出了一种基于CNN和Transformer并行架构的模型,分别提取图像的局部特征和全局表示,更能充分利用不同位置的特征防止其丢失。
因此,受文献[17]研究方法的启发,现提出了CNN-Transformer双流网络模型,目的是将基于CNN局部特征与基于Transformer的全局表示相结合,以增强表示学习。在所设计的CNN分支流中引入空间注意力和通道注意力,加强图像关键特征的提取。两个分支流的中间部分加入特征交互模块MixBlock,将局部特征与全局表示以交互式的方式结合在一起,进一步提升模型进行分类的性能,并在检测后处理图像上具有一定的鲁棒性。
注意力(attention)是一种模仿人类对特定信息认知意识的机制,将关键细节放大,从而更关注数据的本质内容[18]。在计算视觉任务中使用注意力机制,主要目的是为了关注图像中的重要部分并抑制不必要的信息,通过引入注意力能够在训练中提升模型性能。
1.1 通道注意力
通道注意力(channel attention, CA)是利用特征通道间关系,生成通道注意图,如图1所示。由于特征图的每个通道被认为是一个特征检测器[19],对于输入图像,通道注意力集中在图像中“最有意义的”区域部分。结合Zhou等[20]和Hu等[21]的研究,发现同时利用平均池化和最大池化两个特性,可以提高网络的表示能力,而不是单独使用两者中任何一种池化类型。

图1 通道注意力模块Fig.1 Channel attention module

Mc(F)=σ{MLP[AvgPool(F)]+MLP[MaxPool(F)]}
(1)
式(1)中:σ为sigmoid激活函数;AvgPool(F)、MaxPool(F)为池化后的特征图;W0∈R(C/r)×C和W1∈RC×(C/r)分别为MLP的权重,其中r为减少率,C为特征通道维度大小;Mc(F)为通道注意力参数矩阵。
1.2 空间注意力
与通道注意力不同的是,空间注意力(spatial attention, SA)利用特征空间之间的关系生成空间注意图,关注图像中具有信息性的区域部分,与通道注意力互为补充,如图2所示。

图2 空间注意模块Fig.2 Spatial attention module
在计算空间注意力的过程中,首先沿着通道轴进行平均池化和最大池化的操作,并将两者连接起来,以产生有效的特征描述符。接着沿着通道轴应用池操作可以有效突出并显示信息的区域部分[23]。在连接的特征描述符上,应用卷积层生成一张空间注意力图Ms(F)∈RH×W,其中H、W分别表示注意力图的高度和宽度。

Ms(F)=σ(f7×7{[AvgPool(F);MaxPool(F)]})
(2)
式(2)中:F为输入的特征图;σ为sigmoid激活函数;f7×7代表卷积核大小为7×7的卷积运算。AvgPool(F)、MaxPool(F)为池化后的特征图;Ms(F)为空间注意力参数矩阵。
1.3 Transformer和自注意力机制
Transformer是一种基于自注意力机制的模型,由6个编码器和解码器模块组成。不仅在建模全局上下文方面表现强大,而且在大规模预训练下对下游任务表现出卓越的可转移性[24]。其中自注意力[25]机制是注意力机制的改进,减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性,也被用作捕获全局信息的空间注意机制。自注意力在计算机视觉领域上成为主要工具的潜力。


图3 缩放点积注意力Fig.3 Scaled dot-product attention
(3)
式(3)中:Attention()为注意力机制的计算函数;Q为查询向量;K、V为键值对;KT为键向量的转置;Softmax()表示归一化指数函数。
与只单独使用一个注意力相比,Transformer采用由n个缩放点积注意力组成的多头注意力(multi-head attention),使模型能够共同关注不同位置以及不同表征子空间的信息,如图4所示,多头注意力计算公式为

图4 多头注意力Fig.4 Multi-head self-attention
(4)
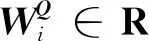
2.1 整体网络框架
在计算机视觉领域中,提取图像的局部特征和全局表示是十分重要的,并不断被广泛研究。为在训练过程中充分利用局部特征和全局信息,提出了一种并行双流网络模型,如图5所示。
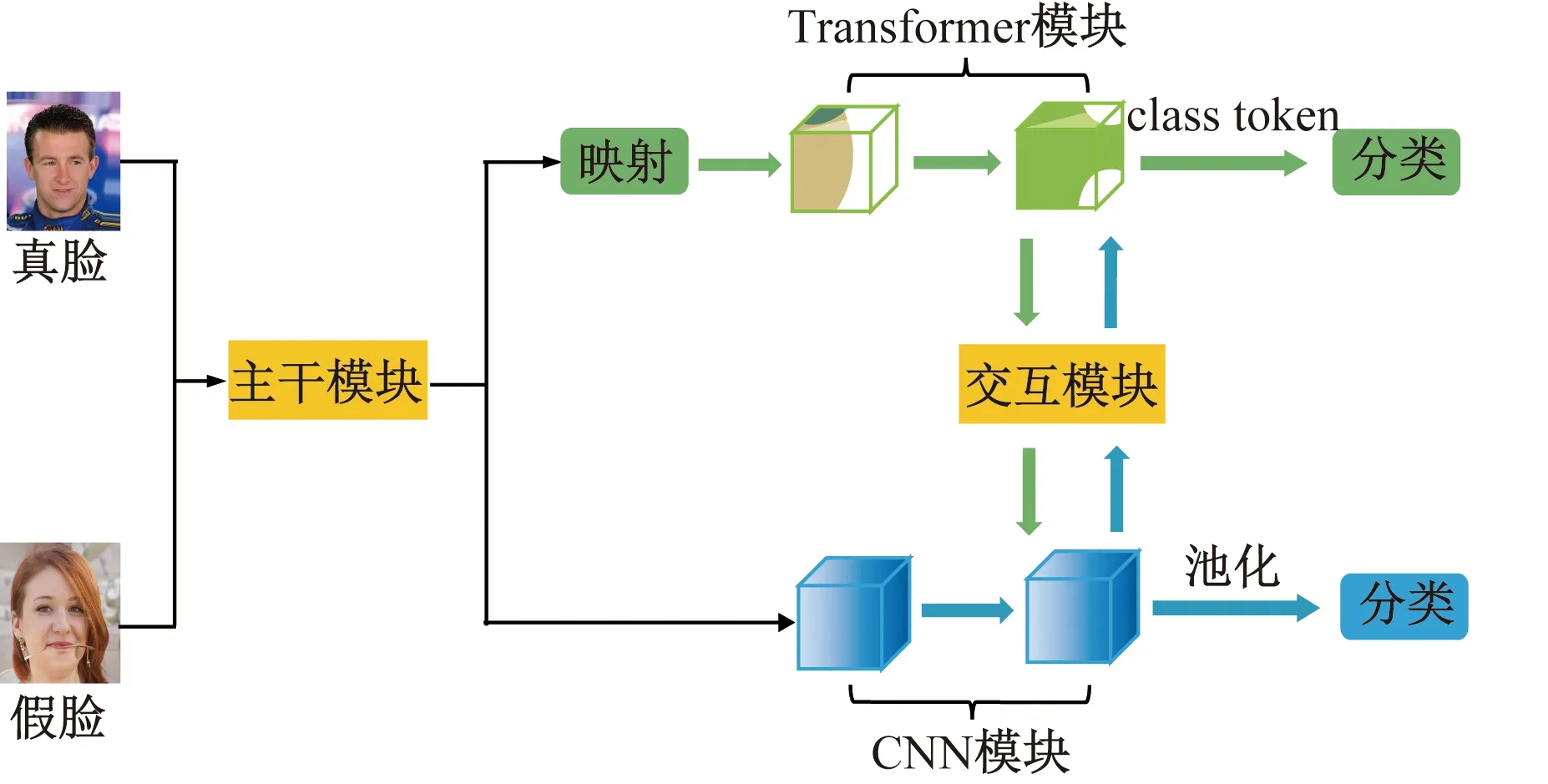
图5 网络框架缩略图Fig.5 Network framework thumbnail
在图5中,CNN-Transformer双流网络框架主要由一个主干模块、双分支、用于桥接双分支的MixBlock交互模块和两个分类器组成。主干模块是由一个步长为2的7×7卷积和一个步长为2的3×3最大池化层组成,用于提取图像初始局部特征,并将特征提供给双分支。对于两条双分支,从Transformer分支中向特征图提供图像的全局表示,以增加CNN分支的全局感知能力。同样,来自CNN分支的局部特征也会被逐步反馈到补丁嵌入中,使Transformer分支中的局部细节变得更加丰富。MixBlock作为一个桥梁模块,将CNN分支中的局部特征和Transformer分支中的全局表示融合在一起,共同构成了交互作用。这样的并行结构可以分别最大限度上保留局部特征和全局表示。
在CNN分支和Transformer分支中分别由12个卷积块和Transformer块组成,由图6所示。其中MHSA(multi-head self-attention)表示Transformer分支流的多头自注意块。CNN块和Transformer块中间的箭头指向代表特征的流程方向,在阶段输出中,例如56×56,197分别表示特征图的大小为56×56,嵌入补丁的数量为197。在最后分类里C-NN分支和Transformer分支分别通过平均池化和class token两个不同分类器输出结果。
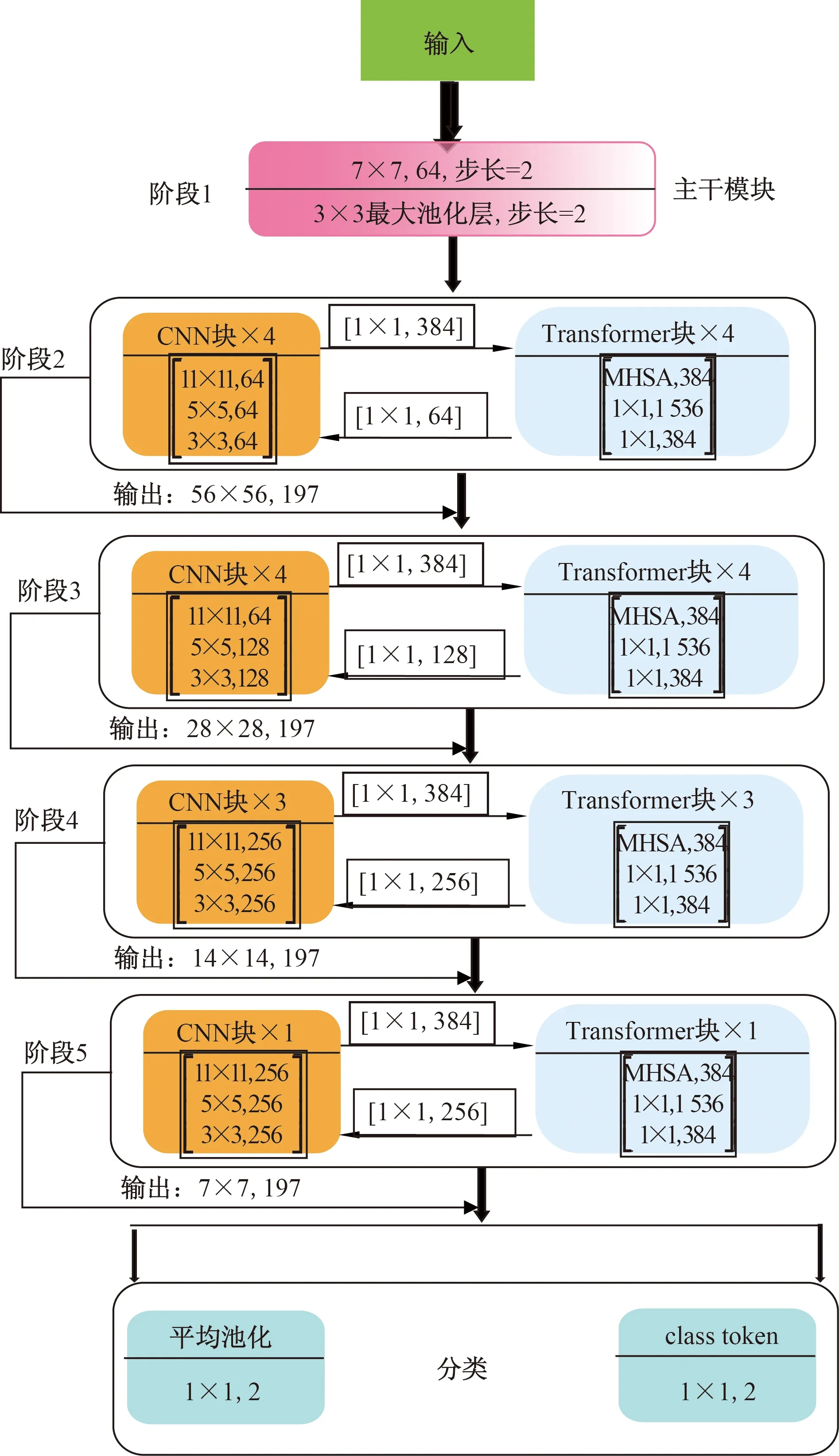
图6 双分支交互图Fig.6 Dual branch interaction diagram
2.2 分支模块设计
2.2.1 CNN分支
在所设计的CNN分支中一共有五层,前面三层为卷积层,卷积核大小逐层递减,分别为11×11、5×5和3×3,目的是训练过程中先增大卷积感受域范围,使其能够在图像上提取更多的特征,在后面利用小卷积核增强模型在提取特征的判别能力,同时减少模型的参数数量,避免增加不必要的计算量。卷积层的后面紧随着是最大池化层,一方面是对卷积层所提取的信息进一步降低维度,另一方面加强图像特征的不变性。
CNN分支结构的第一层以及在卷积层最后一层中通过引入通道注意力和空间注意力,为了能在训练初始阶段与收尾阶段计算图像各个通道的权重,提高捕获真实自然人脸与GAN合成人脸图像的重要区域特征和关键信息的能力。在每层最后使用ReLu激活函数防止训练过程中造成图像部分特征信息的丢失,也在全连接层利用dropout进一步缓解过拟合问题。
由于Transformer分支将图像补丁投影到矢量的过程中导致了局部细节的丢失,而在CNN分支中,卷积核在图像的重叠特征映射上滑动,保留精细的局部特征。因此CNN分支能够连续为Tran-sformer分支提供细节信息,双分支细节图如图7所示。

图7 双分支细节图Fig.7 Double branch detail
2.2.2 Transformer分支
Transformer分支中包含了多个Transformer模块,每个Transformer块由一个多头自注意模块和一个多层感知机(multilayer perce-ption, MLP)块(包含上投影全连接层和下投影全连接层)组成,归一化层应用于每一层、自注意力层和MLP模块中。
2.2.3 MixBlock模块
在进行特征提取和表示的过程中,考虑到CNN分支中的特征映射和Transformer分支的补丁嵌入,两者存在特征维数不一致问题,设计了如图8所示的MixBlock模块,该模块以一种交互的方式,连续耦合图像的局部特征和全局表示。

图8 MixBlock交互模块Fig.8 MixBlock interaction module
在特征维数不一致的问题上,一方面,CNN特征图的维数是C×H×W(C、H、W分别代表通道、高度和宽度),补丁嵌入的形状为(K+1)×E,K、1、E分别为图像补丁个数、class token和嵌入维数。
当特征图从CNN分支送入到Transformer分支时,首先需要通过1×1卷积对齐补丁嵌入的通道数,接着使用下采样模块完成空间尺寸对齐,最后对特征映射进行补丁嵌入。反之当从Transformer分支反馈到CNN分支时,需要对补丁嵌入进行上采样以对齐空间尺度,通道维度通过1×1卷积与CNN特征映射进行对齐,同时使用批归一化模块对特征进行正则化。
3.1 实验环境和参数设置
本次实验是在Windows10系统下完成的,使用的是PyCharm Community 2022版本的软件运行环境,其中Python的版本为3.9,以及使用Pytorc-h 1.11.0的深度学习框架,硬件配置中CPU选用Intel(R)Silver 4210R@2.40 GHz 2.39 GHz双处理器,GPU选用RTX3060 12 GB显卡。
在训练过程中,采用交叉熵作为损失函数,优化器使用随机梯度下降算法,其中学习率设置为0.002。训练数据集的批次大小为32,轮次设为15。
3.2 数据集
实验中的伪造人脸数据集主要来自StyleGAN2、PGGAN和StarGAN。其中StyleGAN2和PGGAN是近几年生成的高质量高分辨率的人脸图像,而StarGAN数据集则是对人脸一些属性特征(如头发、皮肤等)以及面部的表情变化进行操作。
真实自然人脸数据集主要采用CelebA和FFHQ。CelebA包含了10 177个身份和202 599个对齐的人脸图像,而FFHQ是一个高质量的数据集,拥有不同的年龄、性别和种族等类型的人脸。相关数据集的描述和数量等详细信息如表1所示。

表1 实验中使用的数据集Table 1 Datasets used in the experiments
3.3 数据集后处理
实验使用四种常见的图像后处理方法:中值滤波(median filter)、高斯滤波(Gaussian filter)、Jpeg压缩(jpeg compress)和高斯噪声(Gaussian noise)对测试集进行操作。中值滤波的窗口大小分别为3×3(MF3)和5×5(MF5);高斯滤波标准差为0,窗口大小分别为3×3(GF3)和5×5(GF5);jpeg压缩中的质量因子分别设置为85(JPEG85)、90(JPEG90)和95(JPEG95)用于对原始图像进行压缩的处理,同时对原始图像的每个像素分别添加均值为0、标准差为0.3(Noise0.3)、0.6(Noise0.6)和0.9(Noise0.9)的高斯噪声,如表2所示。

表2 图像处理操作类型及其参数Table 2 Types of image processing operations and their parameters
4.1 评价方法
精度是分类模型中最常见的性能度量指标,既适用于二分类,也适用于多分类任务,其数值越接近100%,说明分类性能越好,计算公式为
(5)
式(5)中:Cnum为人脸图片分类正确的数量;而Tnum为人脸图像的总数量。
4.2 消融实验
在所提出的双流网络模型中,保持Transformer分支流条件不变的情况下,进一步验证在CNN分支流里引入通道注意力(CA)模块和空间注意力(SA)模块的必要性,使用StyleGAN2和PGGAN两种不同类型的数据集上进行消融测试,测试结果由表3所示。

表3 消融实验结果Table 3 Ablation experiment results
双流网络模型两条不同的分支流分别通过平均池化和class token方式输出各自的精度:CNN精度和Transformer精度,再把两种不同的精度混合相加并平均输出,得到最后分类的总精度。
由表3可知,相比原始未引入两种注意力的CNN分支,在提取的人脸特征中含有较多空间和通道特征冗余度,分类过程中不能保证较好的鉴别性区分。单独引入CA或SA时,在提取人脸特征上也无法取得满意的效果。而CA和SA在提取特征上具有互补性,使得CNN+TF+CA+SA模型更能集中关注和区分真实自然人脸和GAN合成人脸,精度可高达99.52%。实验表明通过在CNN分支中引入通道注意力和空间注意力,使模型在提取高质量合成人脸的特征上更有鉴别性,也进一步保证了模型的分类精度。
4.3 对比实验
对于测试数据集,为减少图像背景在训练过程中所带来不必要的影响,进而专注检测图像中的人脸。实验选择从每张图像中裁剪出512×512的面部区域去除背景,接着裁剪后的图像使用双线性插值调整为64×64。
为了评价所提方法的有效性,将本文方法的实验结果与文献[26-27]中已有的方法进行了比较,对比结果由表4所示。
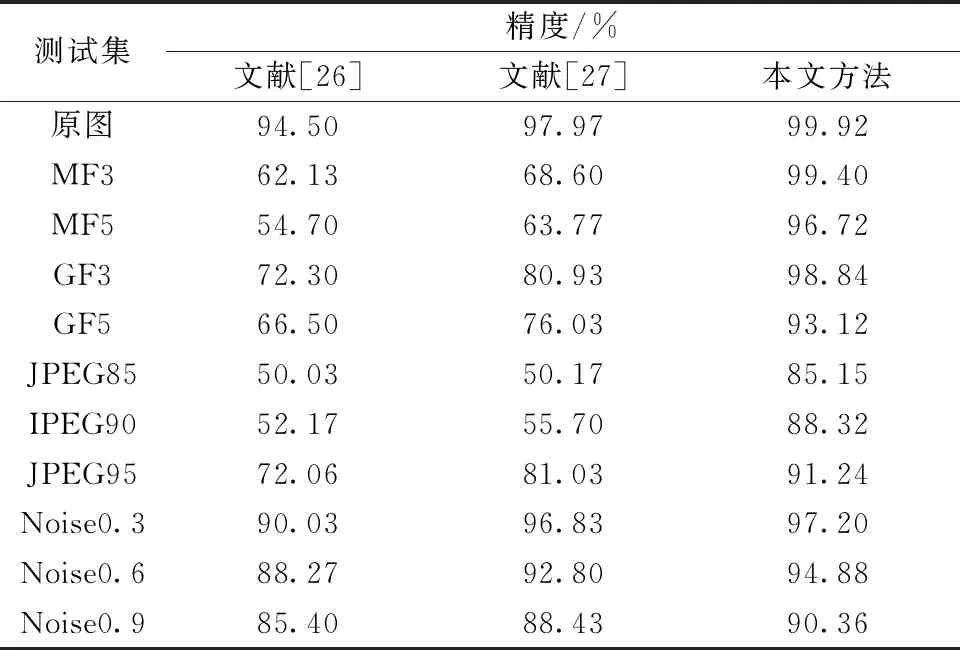
表4 方法对比结果Table 4 Comparison results of methods
在原图各方法的对比结果中,本文方法使用双分支提取人脸图像的局部特征和全局表示上表现出显著的分类性能,分类精度可高达99.92%,优于前面两种现有的方法。然而在生活的实际应用中,图像加噪、jpeg压缩等后处理操作已广泛应用于数字图像中。
对于经过后处理几种不同的测试集,MF集和GF集随着滤波半径的增加,文献[26]中的方法性能下降速度最快,文献[27]中的方法其次,而本文方法的分类精度保持在93%以上。主要原因是中值滤波和高斯滤波削弱了人脸图像中的高频成分,对边缘信息进行平滑,进而表现出一定的模糊效果。文献[26]中的方法只学习了图像高频成分表示,因此在预处理后的图像上分类效果较差,而所提方法在特征交互上可以抑制这些图像后处理操作的影响。对于JPEG集现有两种方法而言, jpeg压缩的质量因子对其检测精度有较大的影响,并且伴随着质量因子的不断缩减,检测精度也随之下降,但与之相比,本文方法的精度能够保持在85%以上。在Noise集,噪声的添加给合成人脸图像的检测带来了多余干扰信息,在局部范围内无法较好区分或遗漏所需的鉴别性特征,而所提方法在全局上弥补了这一局限性,与文献[26-27]方法相比,能够达到90%以上的分类效果。因此,在GAN生成的人脸图像检测中,CNN-Transformer并行双流网络模型比现有的两种方法在检测后处理图像上更具有鲁棒性。
深度学习的发展以及伴随着由GAN合成的人脸图像技术越来越成熟,一定程度上给国家和社会在经济和安全上会造成严重的消极影响。针对合成人脸图像的检测,提出了一种CNN-Transformer并行的双流网络框架,在CNN分支流中引入空间注意力和通道注意力,而Transformer分支流中使用自注意力和多层感知机,训练过程中分别提取图像的局部特征和全局表示,并在中间使用MixBlock模块进行交互。通过在不同的数据集上进行训练并测试,实验结果表明,与现有方法相比,该方法能够取得不错的分类性能,并在后处理图像上能表现出鲁棒性性能。未来会进一步增加数据集的数量和种类,扩展所提方法来检测其他合成的图像。
猜你喜欢分支人脸全局Cahn-Hilliard-Brinkman系统的全局吸引子数学物理学报(2022年4期)2022-08-22量子Navier-Stokes方程弱解的全局存在性数学物理学报(2022年2期)2022-04-26有特点的人脸少儿美术·书法版(2021年9期)2021-10-20巧分支与枝学生天地(2019年28期)2019-08-25三国漫——人脸解锁动漫星空(2018年9期)2018-10-26落子山东,意在全局金桥(2018年4期)2018-09-26一类拟齐次多项式中心的极限环分支数学物理学报(2018年1期)2018-03-26马面部与人脸相似度惊人发明与创新(2015年33期)2015-02-27新思路:牵一发动全局中国卫生(2014年5期)2014-11-10长得象人脸的十种动物奇闻怪事(2014年5期)2014-05-13本文来源:http://www.triumph-cn.com/fanwendaquan/gongwenfanwen/2023/0927/109491.html